- Learners can import data from files in CSV and XLSX format located in sub-directories of the root directory.
- Learners can explain the difference between the vector class character and the vector class factor.
- Learners can discuss the difference between unprocessed raw data, processed analysis-ready data, and data underlying a publication.
- Learners can apply 12 principles for data organisation in spreadsheets to the layout of a provided dataset.
Data import & Data organization in spreadsheets
ds4owd - data science for openwashdata
2023-11-21
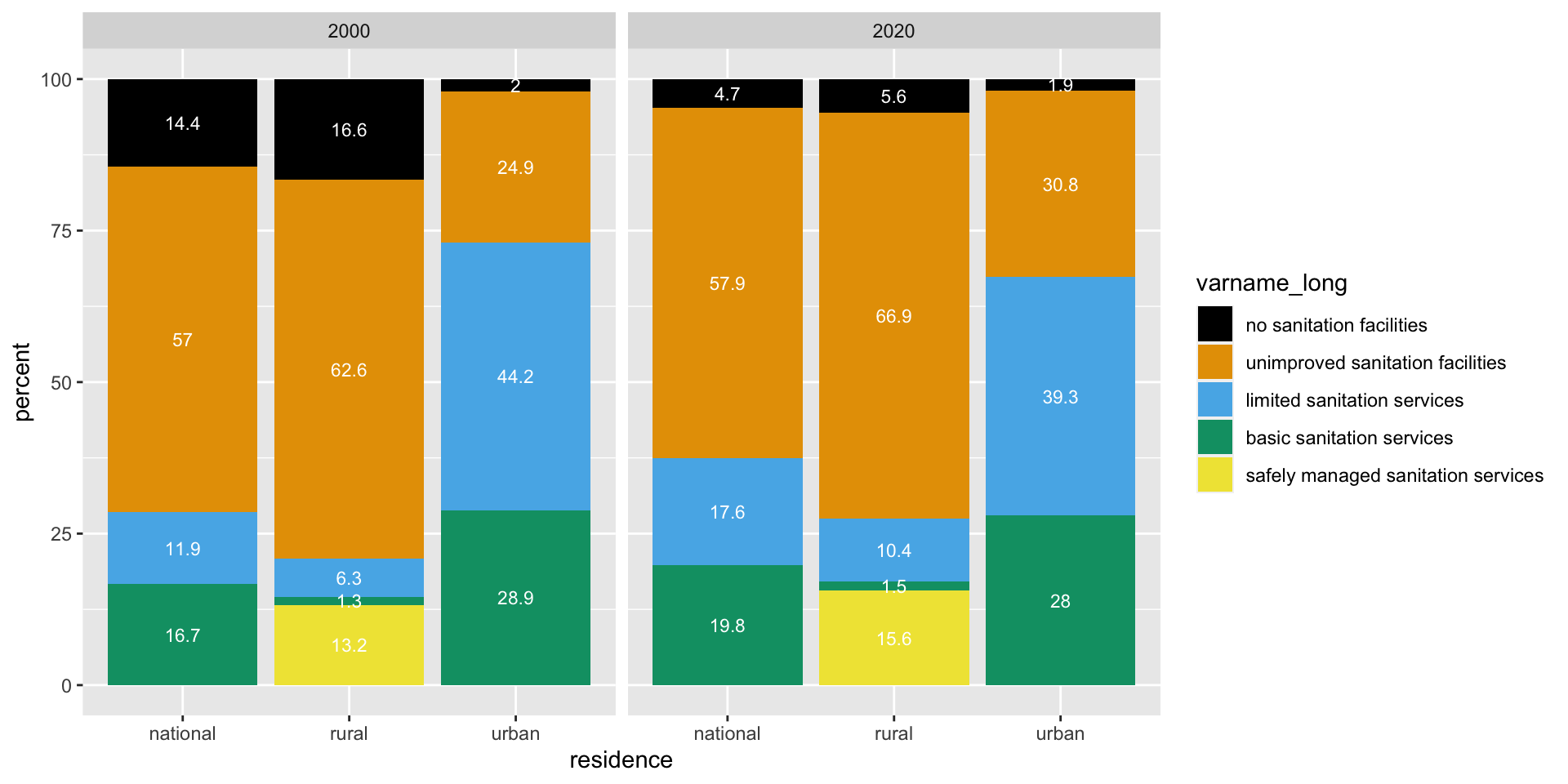
Task 5 & 6: Make a plot & inspect it
- Look at the plot that you created. What do you notice about the order of the bars / order of the legend?
- What would you want to change?
- Why did we remove “safely managed sanitation services” from the data set in Task 3?
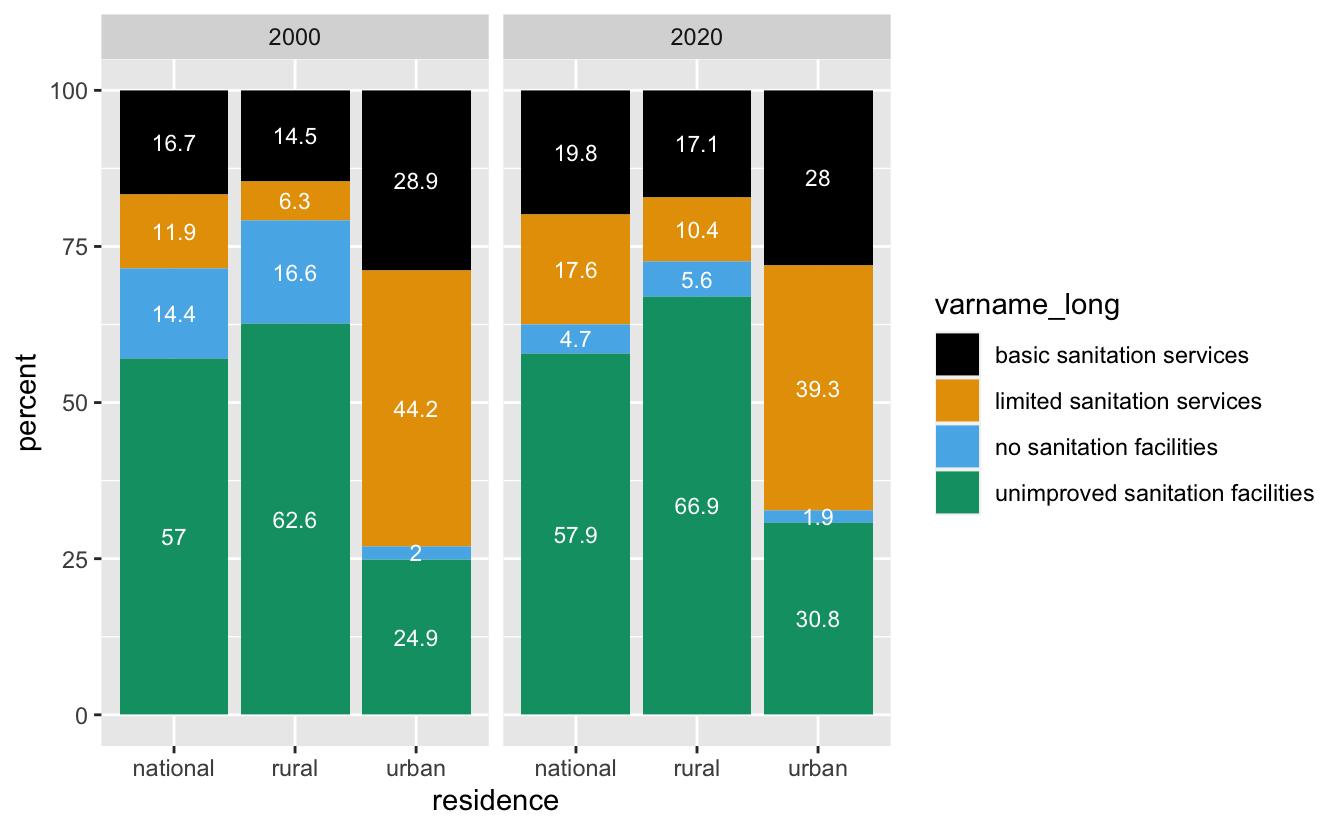
Task 5 & 6: Make a plot & inspect it
- Look at the plot that you created. What do you notice about the order of the bars / order of the legend? alphabetical order
- What would you want to change? put in order of the “sanitation ladder”
- Why did we remove “safely managed sanitation services” from the data set in Task 3?

Task 5 & 6: Make a plot & inspect it
- Look at the plot that you created. What do you notice about the order of the bars / order of the legend? alphabetical order
- What would you want to change? put in order of the “sanitation ladder”
- Why did we remove “safely managed sanitation services” from the data set in Task 3?
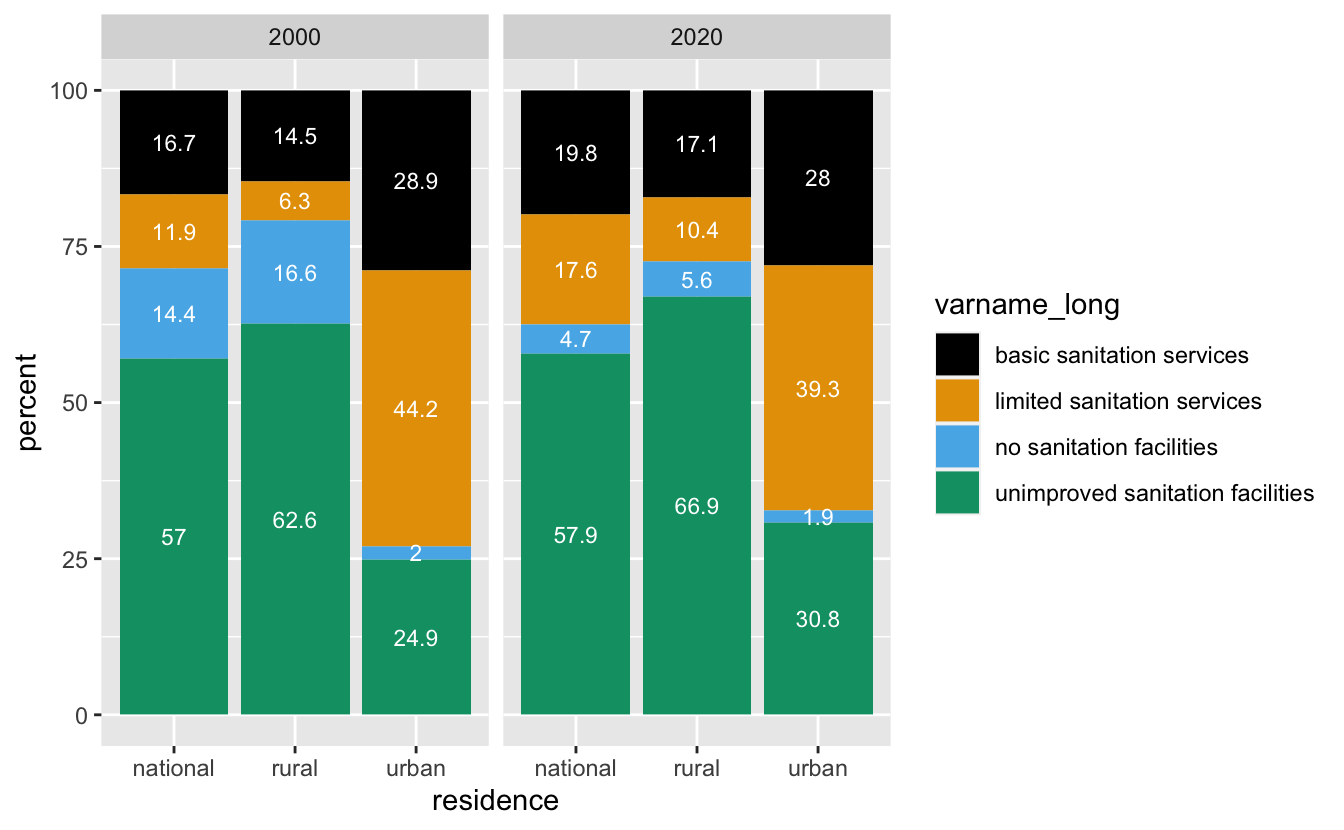
Task 5 & 6: Make a plot & inspect it
- Look at the plot that you created. What do you notice about the order of the bars / order of the legend? alphabetical order
- What would you want to change? put in order of the “sanitation ladder”
- Why did we remove “safely managed sanitation services” from the data set in Task 3?
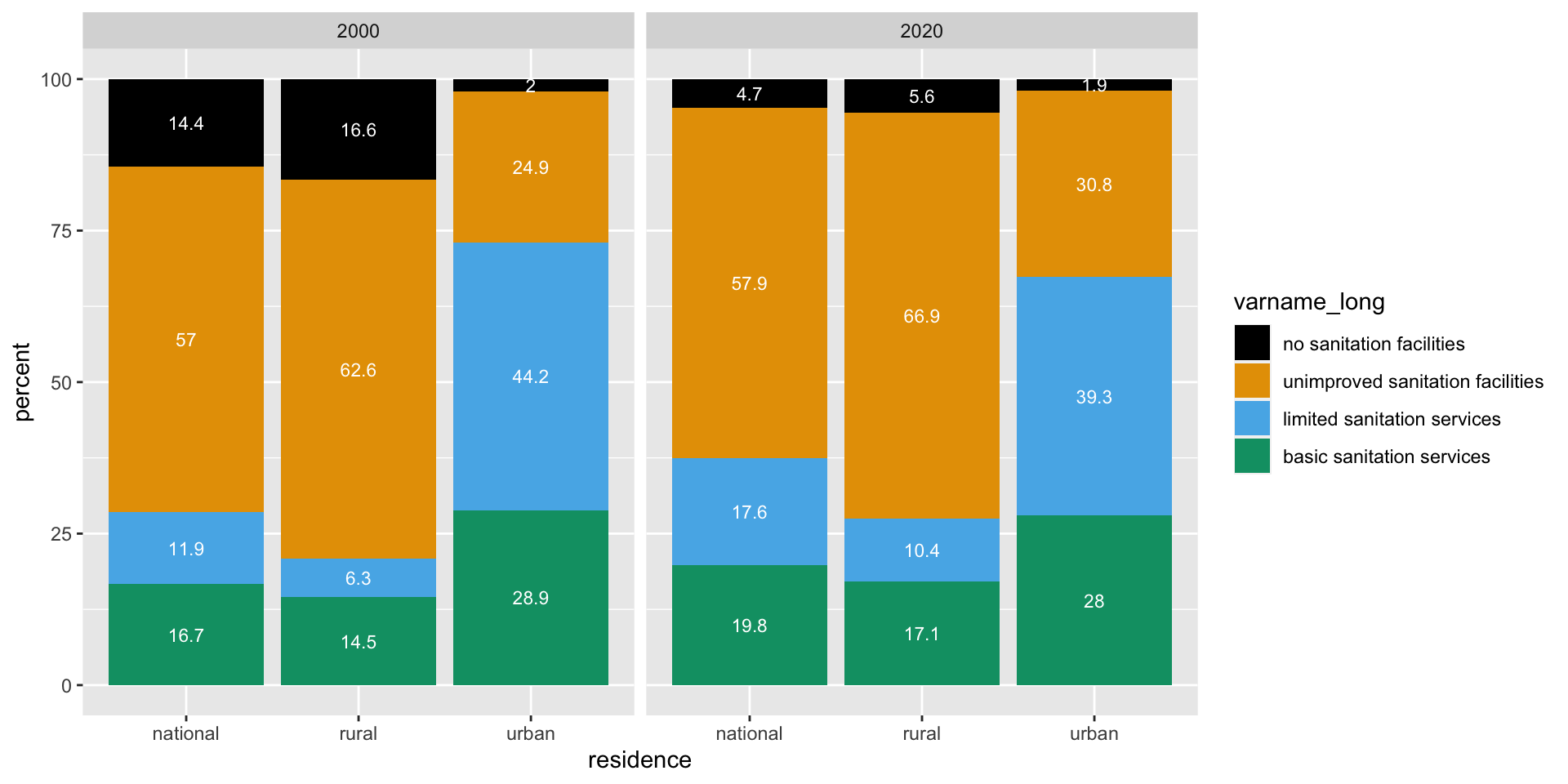
Task 5 & 6: Make a plot & inspect it
- Look at the plot that you created. What do you notice about the order of the bars / order of the legend? alphabetical order
- What would you want to change? put in order of the “sanitation ladder”
- Why did we remove “safely managed sanitation services” from the data set in Task 3? because the total adds up to greater 100%, a fraction of people with basic services have safely managed services
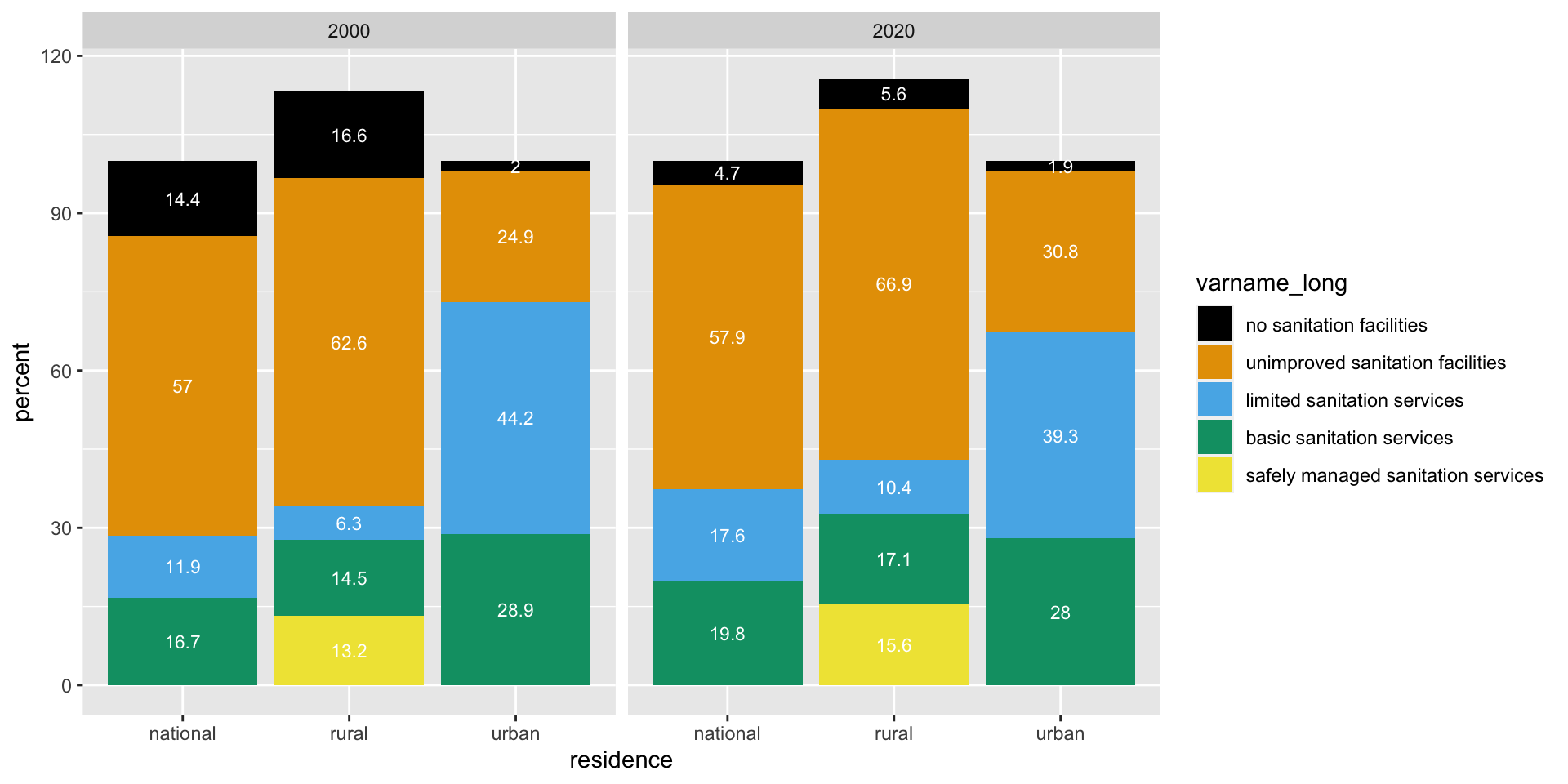
Task 5 & 6: Make a plot & inspect it
- Look at the plot that you created. What do you notice about the order of the bars / order of the legend? alphabetical order
- What would you want to change? put in order of the “sanitation ladder”
- Why did we remove “safely managed sanitation services” from the data set in Task 3? because the total adds up to greater 100%, a fraction of people with basic services have safely managed services
Take a break
Please get up and move! Let your emails rest in peace.
10:00
Reading rectangular data into R

Take a break
Please get up and move! Let your emails rest in peace.
10:00
Data Organization in Spreadsheets
Data Organization in Spreadsheets
Why? Because following a set of rules for organizing data everyone’s live a little better.
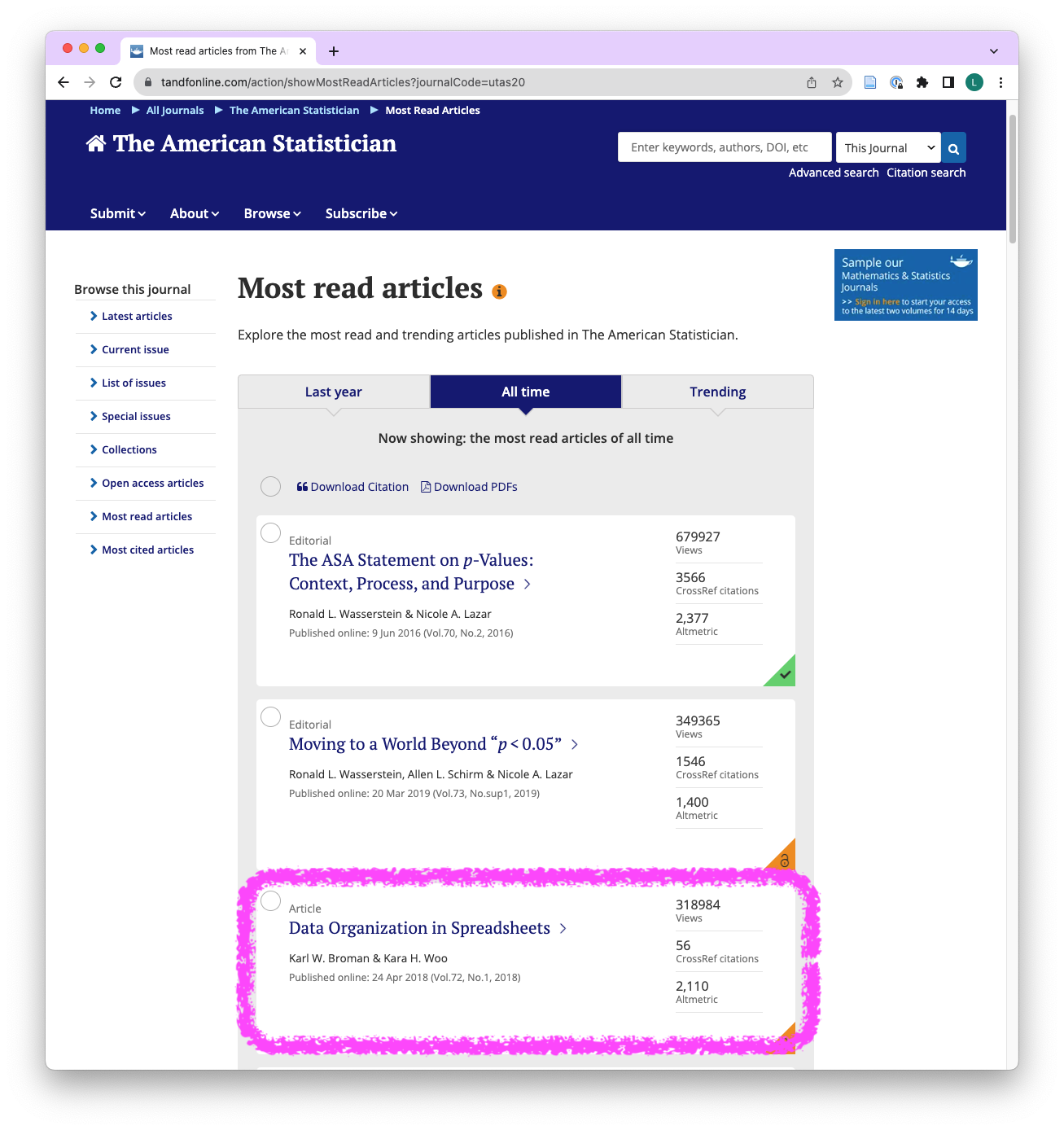
- 3rd most viewed paper on The American Statistician
- 310’000+ views
- widely accepted as minimal standards
Data Organization in Spreadsheets
License? CC0 (!)
Thanks! 🌻
Slides created via revealjs and Quarto: https://quarto.org/docs/presentations/revealjs/ Access slides as PDF on GitHub
All material is licensed under Creative Commons Attribution Share Alike 4.0 International.
![]()